Monitoring Applications
After you deploy your application you can utilize the platform to monitor the performance of your applicaiton.
To access the performance metrics navigate to the Monitoring Dashboard on the applications overview page.

Through the right drop down in the header, you can select the timeframe for the metrics.
Through the left drop down in the header, you can select which variants of the application you want to view the metrics for.


The tabs on the sub header allows you to toggle between Interactions, Engagements, and Executions.
Interactions
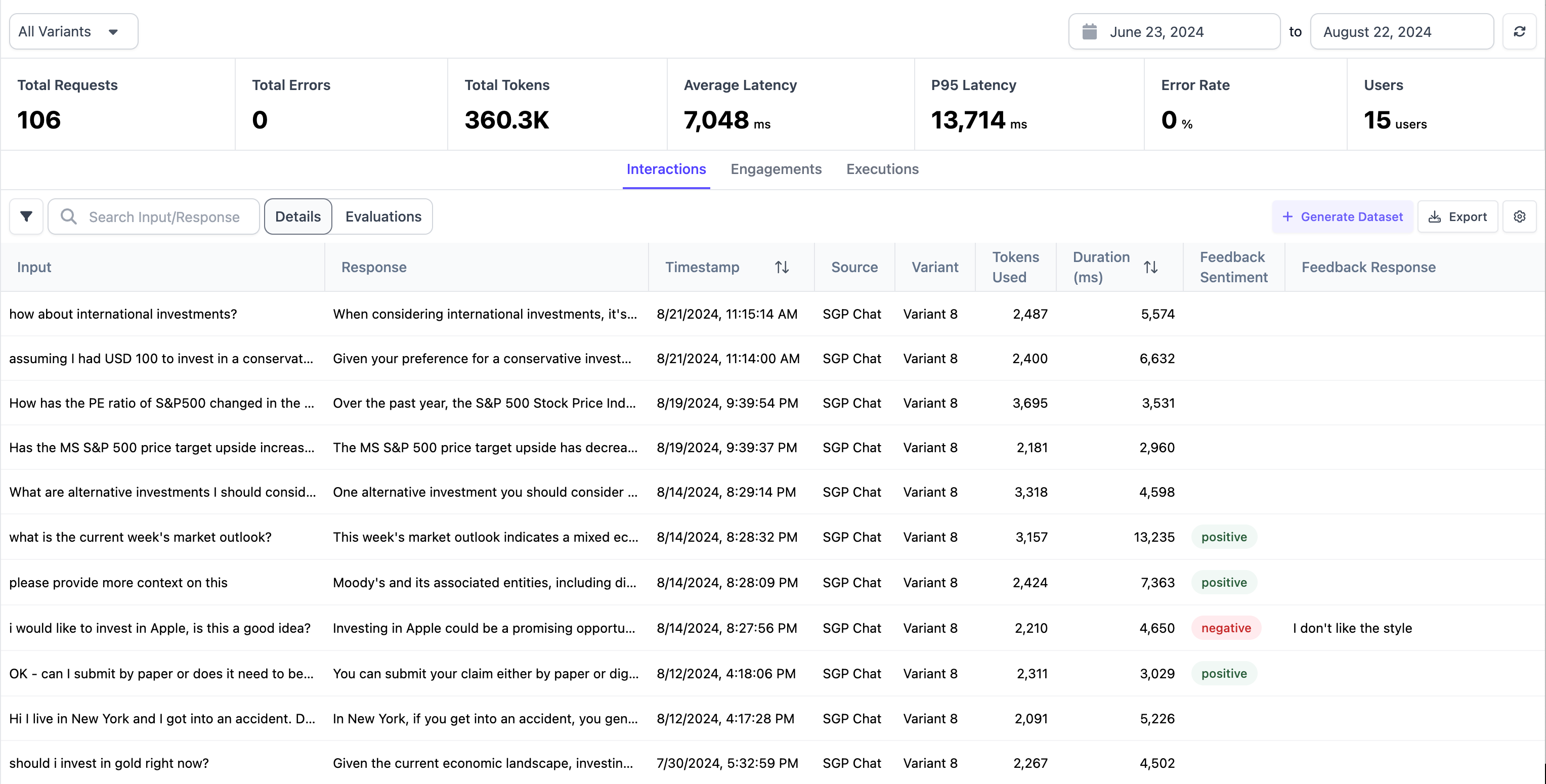
From the Interactions tab, you can see specific interactions users have with your application in the table. You can see an itemized list of the User Input, Application Response, when the interaction took place, and the tokens used by your application.
The Chat application also has a spot for users to give their feedback sentiment through thumbs up or thumbs down and also to provide qualitative feedback. This will show up under Feedback Sentiment and Feedback Response respectively.
On top of the table, you can see a summary of all the aggregated metrics.
Engagements
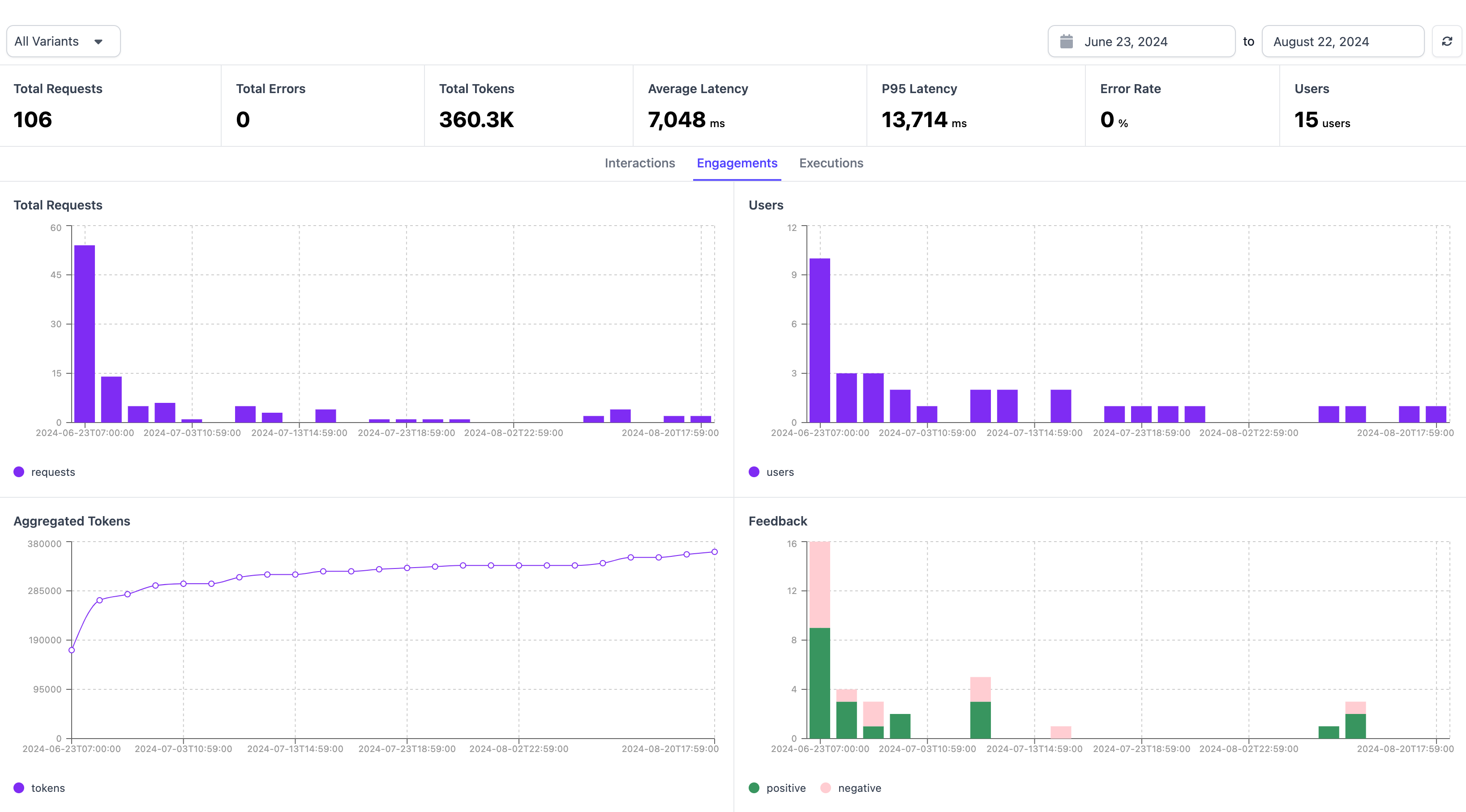
The engagement tab has an aggregate view of metrics in graphical form. We show the distribution of Feedback, User interactions, Aggregated Tokens, and Total Requests in this view.
- Total Requests: These are the total number of messages sent by users of your chatbot in the given timeframe
- Users: These are the total number of unique users in the given timeframe
- Aggregated Tokens: This is the total number of tokens (both input and output) utilized by your application in the given timeframe
- Feedback: This summarizes the positive and negative feedback from users using the chatbot (Thumbs up vs Thumbs down)
Executions
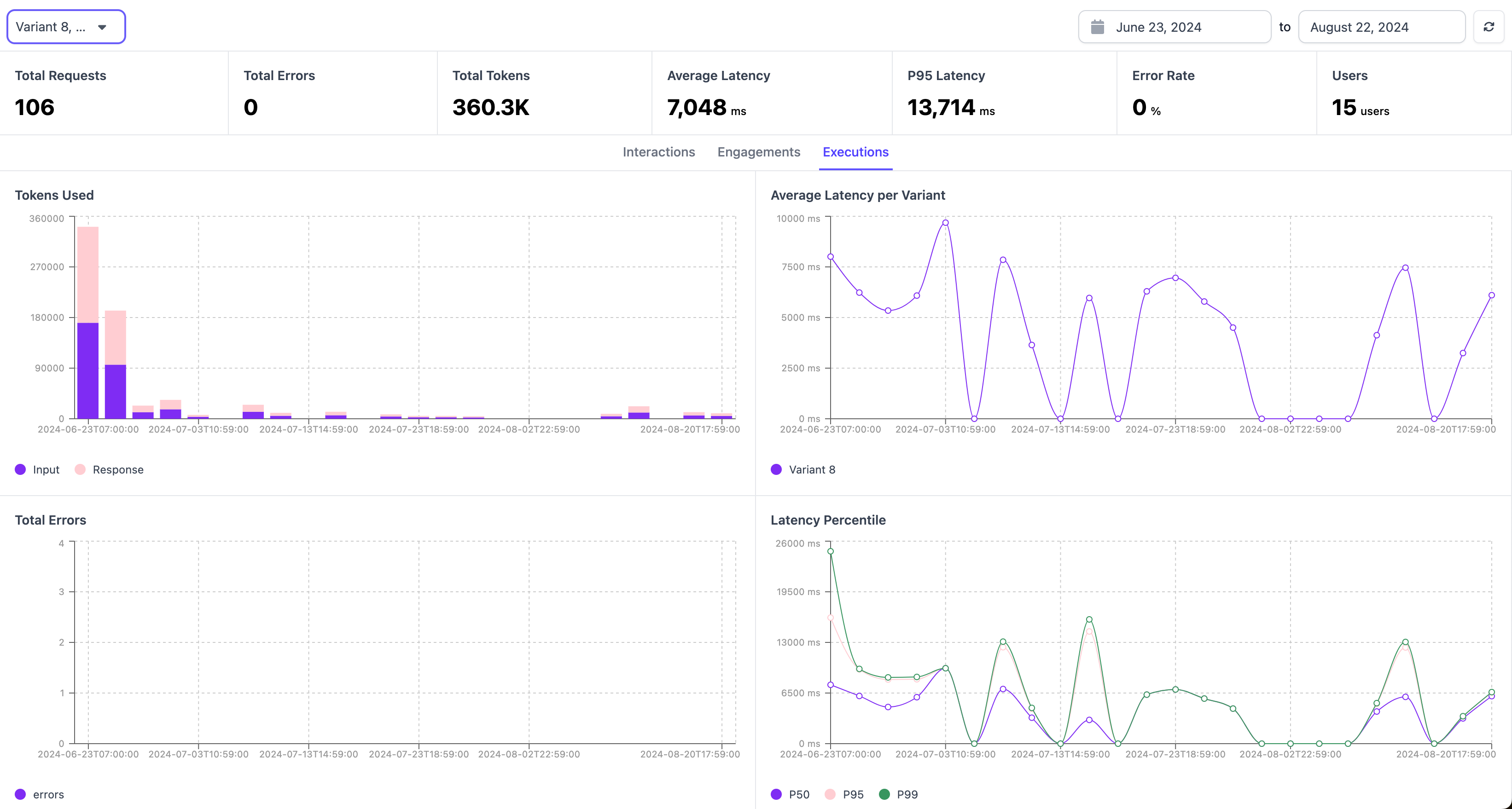
The executions panel gives you an overview on the performance of your application. It shows all the tokens used, any detected errors, latency, and the percentile of latency.
This section can be used to understand how fast your application is and if it has triggered any errors.
Latency Per Node
For a specific variant, you can also see the average latency for each node in that application.
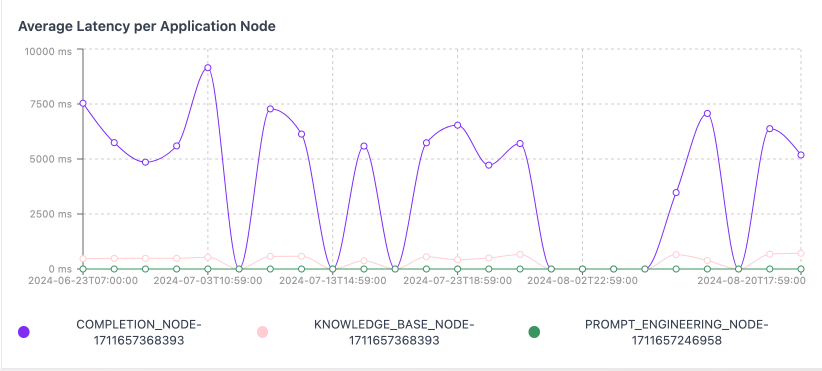
In this example, you can see that the completion node has the highest latency on average, and the prompt engineering node has the lowest latency. This can be used to understand where your application can make latency improvements.
Updated over 1 year ago