Release Notes - 2/23/24
Version 0.9.1
New Features
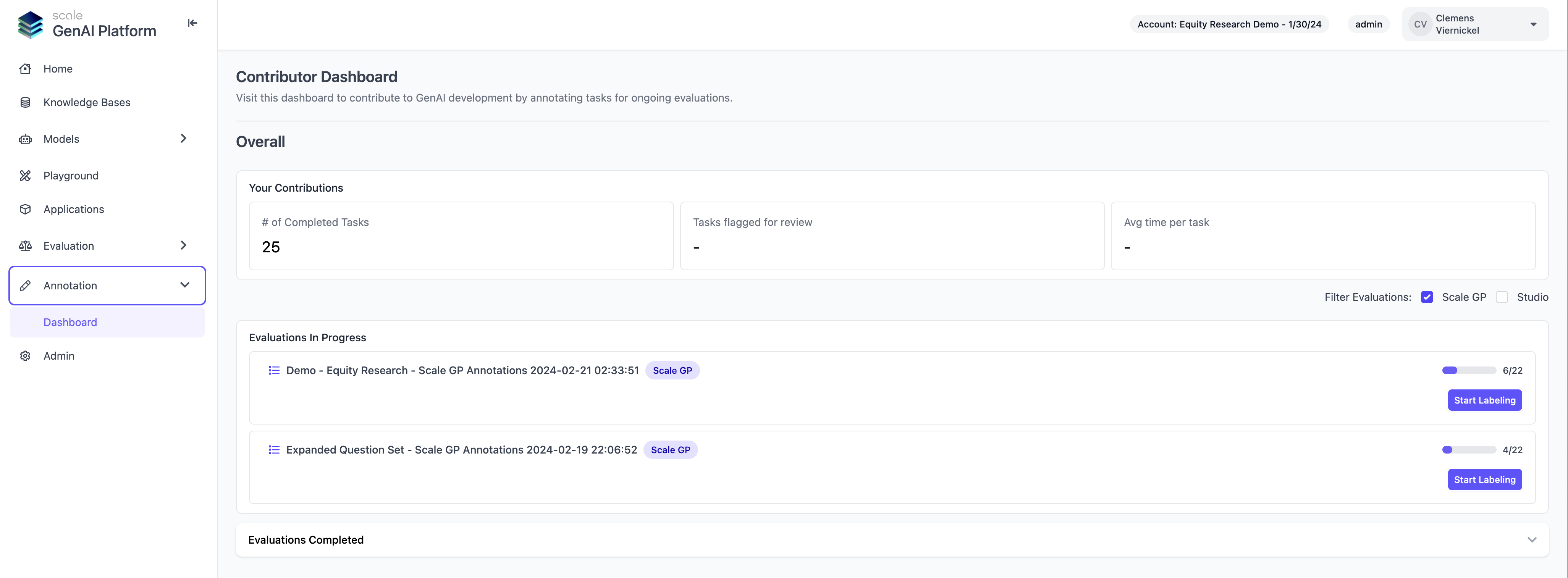
1. End to end Annotation Functionality in ScaleGP
Users now have the ability to conduct human-expert evaluations entirely within Scale GP, eliminating the need to switch to Scale Studio as previously required. This capability is made possible through the implementation of a new task queuing backend and a user interface designed to facilitate the viewing and initiation of evaluation tasks. Features allowing users to prioritize annotation projects and assign annotators to those projects are scheduled for release in the near future.
To facilitate seamless annotation workflows, Scale GP offers role based access control with three user roles: Admin, Manager and Annotator. Managers and Admins will be able to interact with the entire Scale GenAI Platform and manage evaluation runs, including assigning annotation projects and priorities, while annotators (typically SMEs) can focus entirely on the evaluation tasks
How to Use
To get started, users can switch to the new “Annotation” tab on the sidebar and view currently active annotation projects that are ready for labeling. The view also allows users to view legacy annotation projects which are executed using the external Scale Studio queuing system
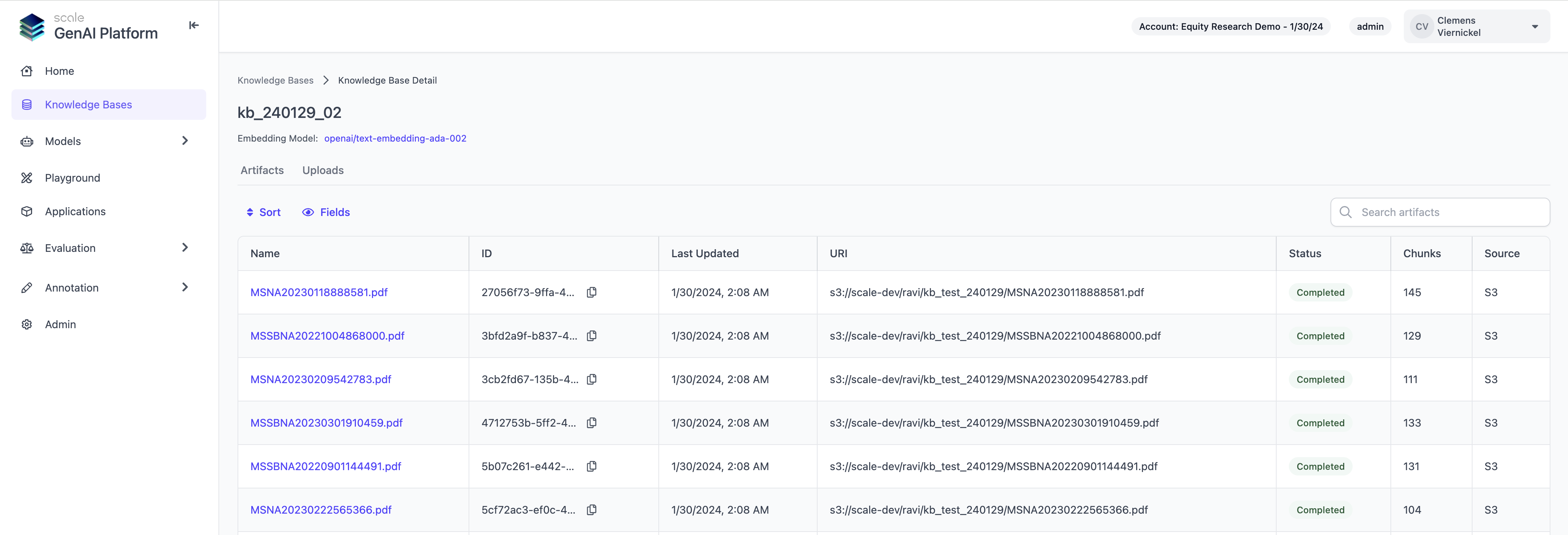
2. Knowledge Base Management
Users can now create and manage their Scale GP knowledge bases via the UI. This makes it significantly easier to monitor the assets uploaded in a knowledge base and to track longer uploads as they are progressing. It also enables users to quickly find and use a relevant knowledge base using the AI playground or when building a custom application with our SDK
How to Use
To get started navigate to the “Knowledge Bases” tab on the left to see your existing resources. If there are none, you can create a new knowledge base via the API or directly in the UI, by uploading assets from your local device. We will soon follow up with automated ingest from data sources like S3 and Azure Blob storage
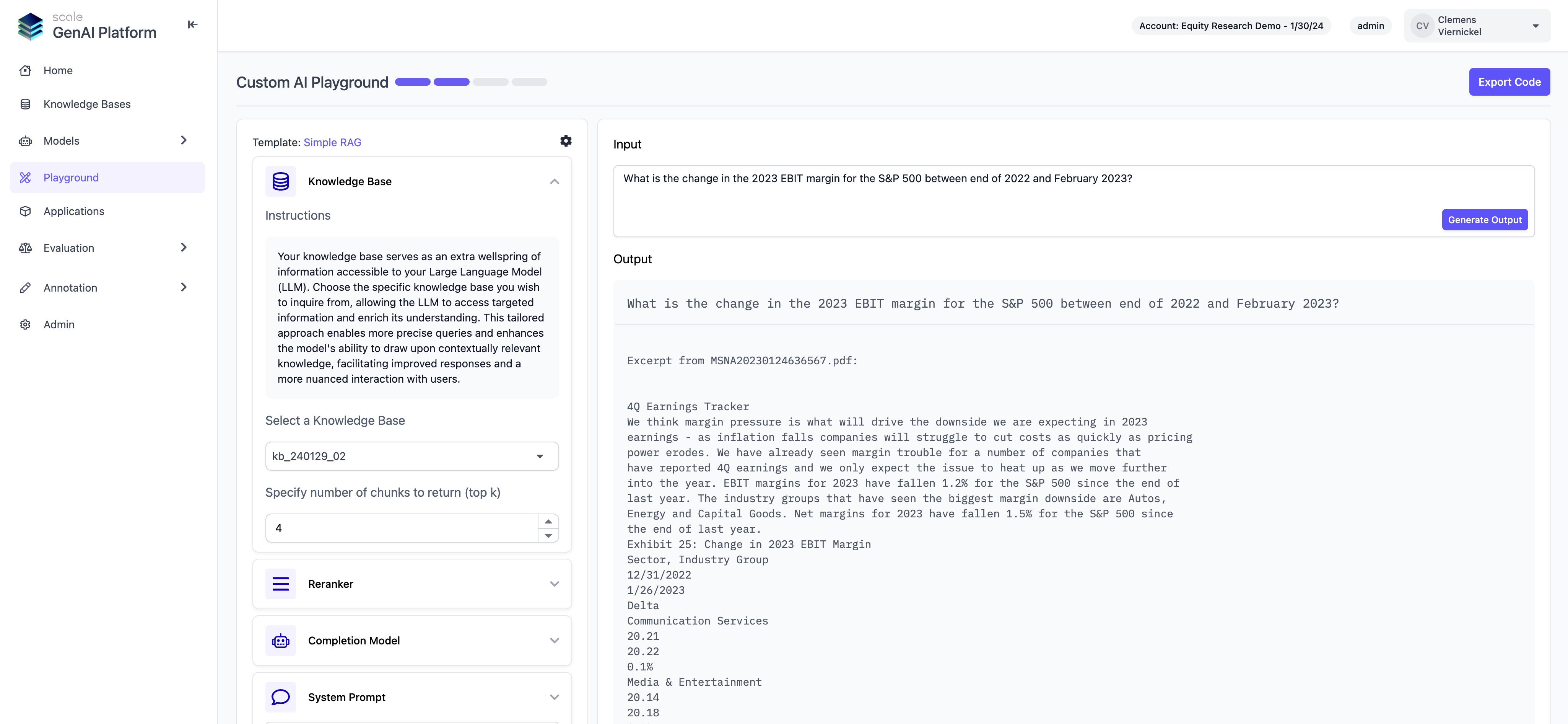
AI Playground
Users can now seamlessly build sample GenAI applications in Scale GP without writing a single line of code. The AI playground provides application templates for typical GenAI use cases such as Retrieval Augmented Generation (RAG), which can be configured in a no-code setup flow, selecting any of the knowledge bases and models that are available on the platform. After completing a setup, users can easily export the sample application for further customization or deployment.
How to Use
To build your first application, switch to the “Playground” tab and begin by selecting a template to configure, then follow the instructions and experiment with components until the desired outcome is achieved.
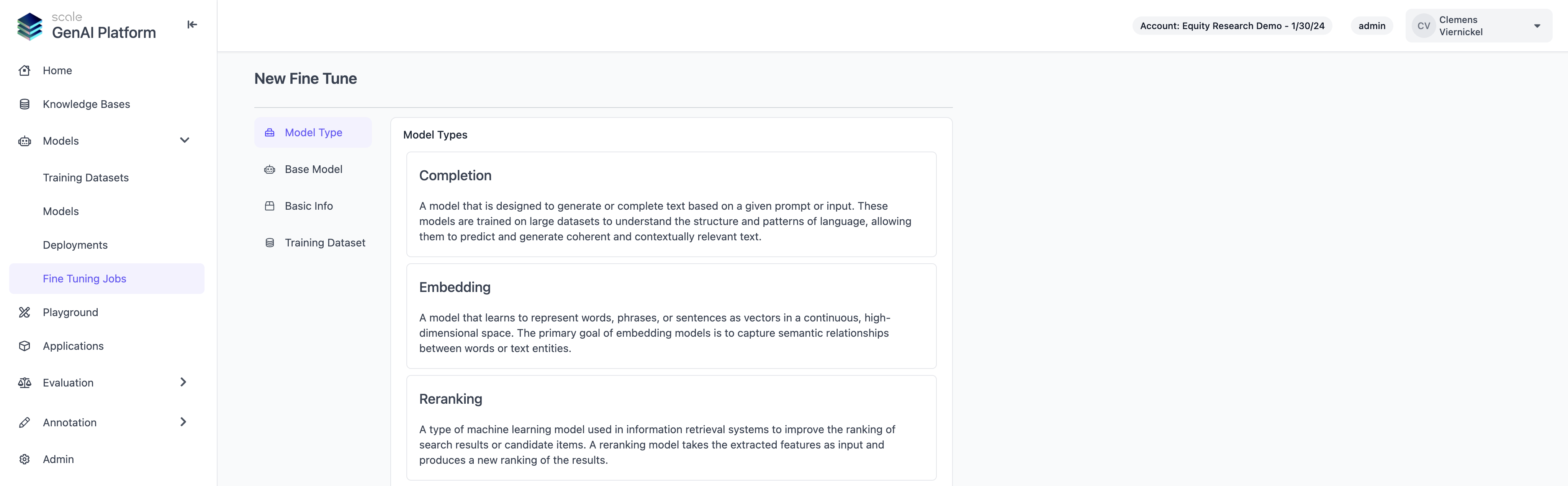
Self-Service Model Fine Tuning
Restructured the annotation view to show generated and expected output, as well as context side by side, which helps annotators compare results to ground truth more efficiently. We will also soon be adding functionality to better navigate retrieved context chunks and a simplified flow to copy sections from context into the evaluation form.
How to Use
To get started with fine tuning your own model, you can click “Create New Fine-Tune” on the “Models” page and follow the steps, or you can use our API or SDK. Note that you will need an correctly formatted training dataset to create a new fine-tune. Please refer to the API documentation for further guidance on dataset format.
After creating a new fine-tuning job, you can monitor the progress on the “Fine Tuning Jobs” page. When a fine tune is completed, it will automatically appear as a new model on the “Models” page.
Enhancements
More Efficient Annotation Interface
Restructured the annotation view to show generated and expected output, as well as context side by side, which helps annotators compare results to ground truth more efficiently. We will also soon be adding functionality to better navigate retrieved context chunks and a simplified flow to copy sections from context into the evaluation form.
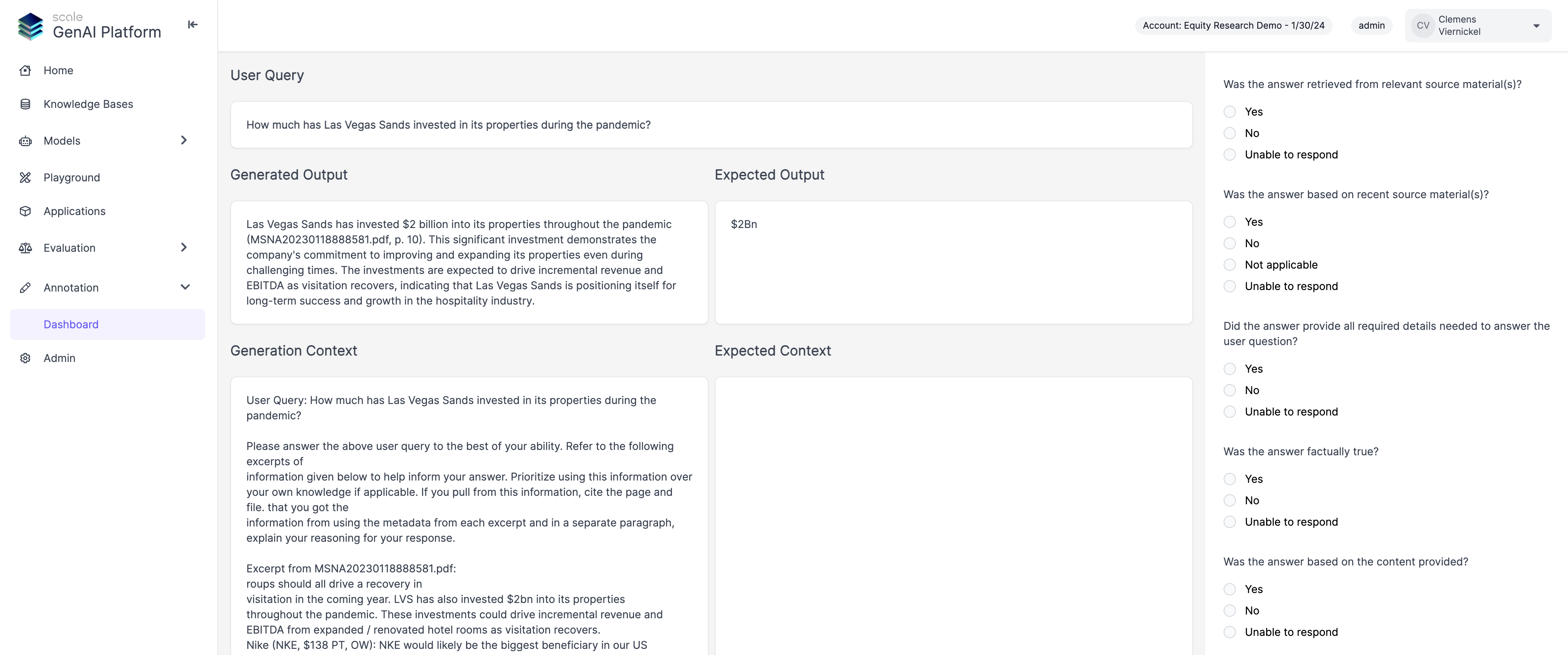
How to Use
To try the new evaluation layout, you can go to “Annotation” and start labeling any “Scale GP” project.
Reports for Evaluation Results and Annotator Performance
Users are now able to see metrics and charts for evaluation runs, which makes it significantly easier to analyze results, track progress and identify regressions. We currently support charts and metrics for each individual evaluation run, as well as for the collection of all evaluation runs of a single application over time. Admin and manager users can also download reports for further analysis and record keeping.
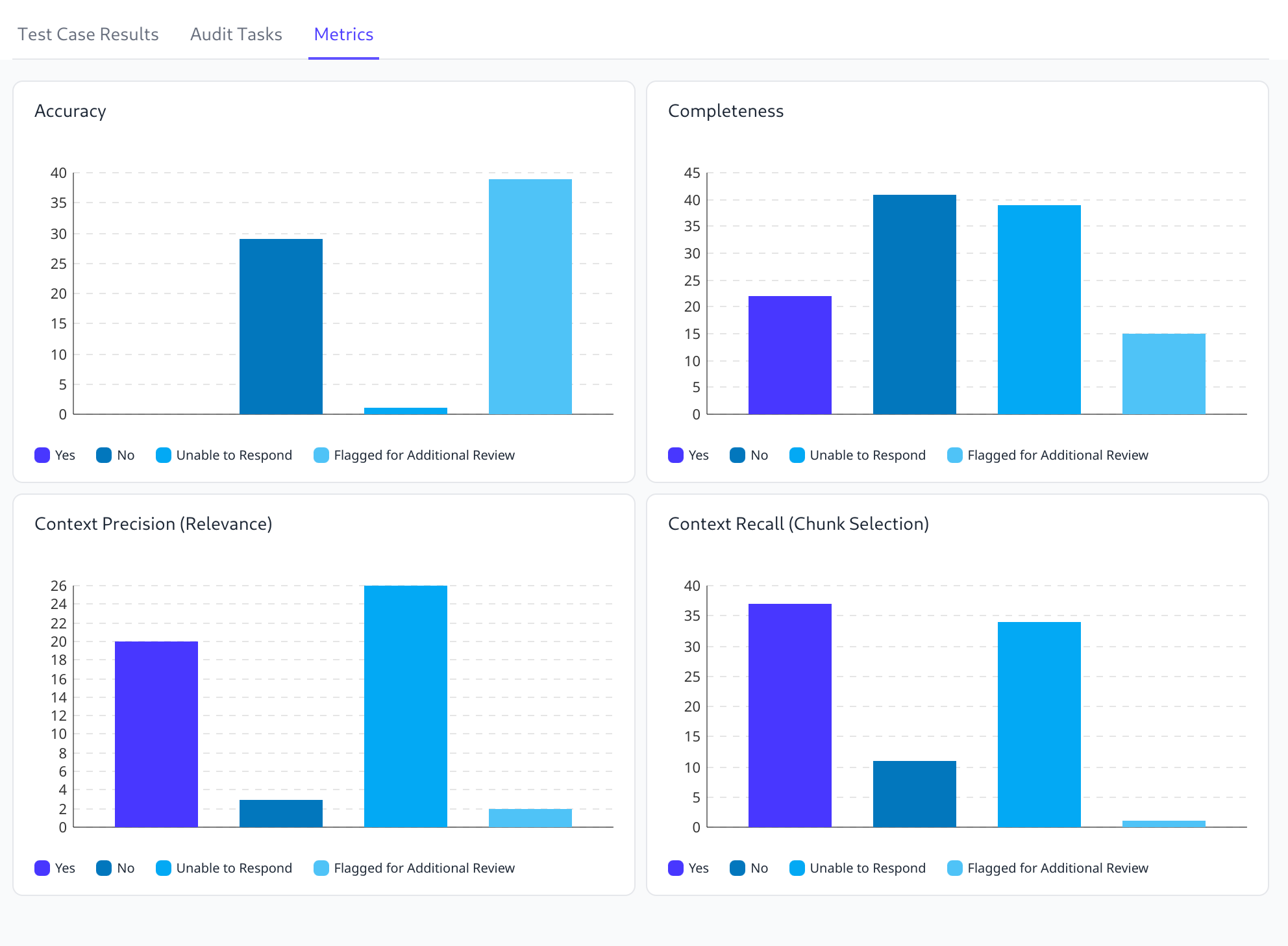
How to Use
To find evaluation reports, you can either go to a single “Evaluation Run” and switch to the “Metrics” tab, or go to an “Application Detail” page and switch to the “Metrics” tab.
Other Updates
Cloud Platform Deployment
Scale GP can now be fully privately deployed in single-tenant environments for both Microsoft Azure and Amazon Web Services.